[01/21/2026] Invited talk at Stanford.
[12/02/2025] Invited talk in NeurIPS tutorial .
[11/20/2025] Guest lecture at NYU.
[10/21/2025] Guest lecture at UC Berkeley & UCSF.
[10/20/2025] Invited talk at ICCV workshop.
[09/25/2025] Invited talk at Princeton.
[09/24/2025] Invited talk at Cornell Tech.
[09/22/2025] Invited seminar talk at Cornell.
[09/17/2025] Invited talk at Allen Institute for AI .
[09/15/2025] Invited talk at CMU VASC Seminar .
[09/08/2025] Guest lecture and invited talk at UMich.
[09/05/2025] Invited seminar talk at UIUC.
[08/22/2025] Invited seminar talk at Caltech.
[08/01/2025] Invited talk at UW.
[07/03/2025] Invited talk at 1X .
[06/12/2025] Invited talk at CVPR 2025 workshop .
[10/28/2024] Invited talk at MIT.
[09/30/2024] Guest lecture at UC Berkeley.
[08/16/2024] Awarded EECS Rising Star in MIT .
[09/29/2024] Invited talk at ECCV 2024 workshop .
[06/18/2024] Invited talk at CVPR 2024 workshop .
[03/08/2024] Invited talk at UPenn GRASP Seminar .
[03/07/2024] Guest lecture at UPenn.
[01/25/2024] Invited talk at Adobe.
[01/23/2024] Invited talk at UT Austin.
[01/16/2024] Invited talk at Distinguished AI Lecture Series at Imperial College London .
[12/06/2024] Invited talk at CMU.
[12/03/2024] Invited talk at UCSD.
[11/15/2023] Invited talk at UMD.
[10/25/2023] Awarded Machine Learning Rising Star in UMD .
[09/18/2023] Awarded EECS Rising Star in Georgia Tech .
[03/02/2023] Awarded Apple Fellowship .
[06/21/2022] Awarded CVPR Best Paper Finalist.
Research Vision
I aim to build intelligent systems from first principles : systems that do not merely fit patterns or follow instructions, but that gradually develop structure, abstraction, and behavior through learning itself .
I'm interested in how intelligence emerges, not from handcrafted pipelines or heuristics tailored to specific tasks, but from exposure to behaviorally rich, understructured environments, where models must learn what to attend to, how to reason, and how to improve. This requires designing learning systems that are not narrowly optimized for a goal, but that can organize themselves and grow increasingly competent through interaction, experience, and computation.
I see scale as a tool , but not as the whole solution. Larger models open up more capacity, but what fills that capacity and how it forms is just as important. My research explores how we can use scale to amplify the right signals: not just data quantity, but the structural richness of behavior , and the dynamics of learning itself.
To that end, I focus on:
Understanding what makes behavior intelligent , especially when it's easy for humans but hard for machines;
Designing systems that learn internal structure from raw behavioral input , without task scaffolds or dense supervision;
Creating conditions where models discover abstraction and reasoning , not because they are explicitly told to, but because learning leads them there.
I believe intelligence is not something we can fully define or supervise in advance. It must emerge over time, shaped by data, computation, and inductive processes inside the model. My work is an attempt to understand and enable that emergence.
Your browser does not support the video tag.
Whole-Body Conditioned Egocentric Video Prediction
Yutong Bai *, Danny Tran *, Amir Bar *, Yann LeCun † , Trevor Darrell † , Jitendra Malik †
Sequential Modeling Enables Scalable Learning for Large Vision Models
Yutong Bai *, Xinyang Geng *, Karttikeya Mangalam , Amir Bar , Alan Yuille , Trevor Darrell Jitendra Malik Alexei A. Efros
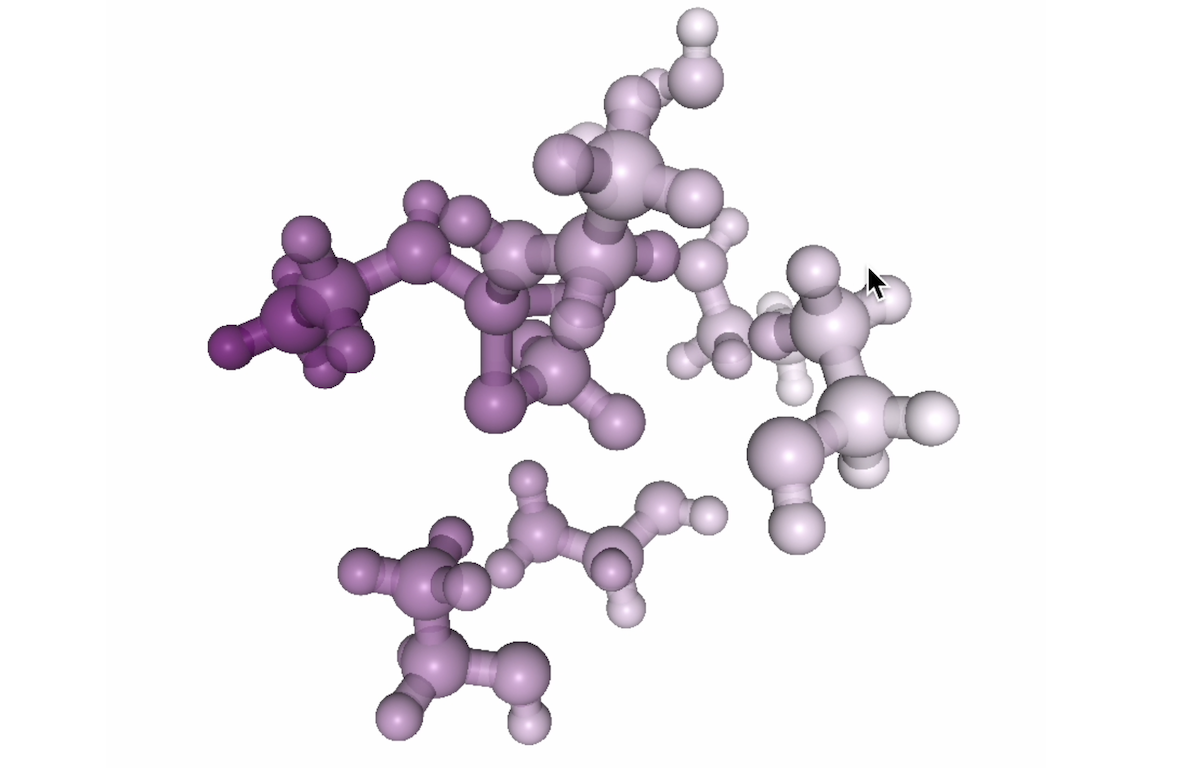
Transformers Discover Molecular Structure Without Graph Priors
Tobias Kreiman Yutong Bai , Fadi Atieh , Elizabeth Weaver , Eric Qu , Aditi S. Krishnapriyan
The Serial Scaling Hypothesis
Yuxi Liu , Konpat Preechakul , Kananart Kuwaranancharoen , Yutong Bai
TARDIS STRIDE: A Spatio-Temporal Road Image Dataset and World Model for Autonomy
Héctor Carrión *, Yutong Bai *, Víctor A. Hernández Castro *, Kishan Panaganti , Ayush Zenith , Matthew Trang , Tony Zhang , Pietro Perona Jitendra Malik
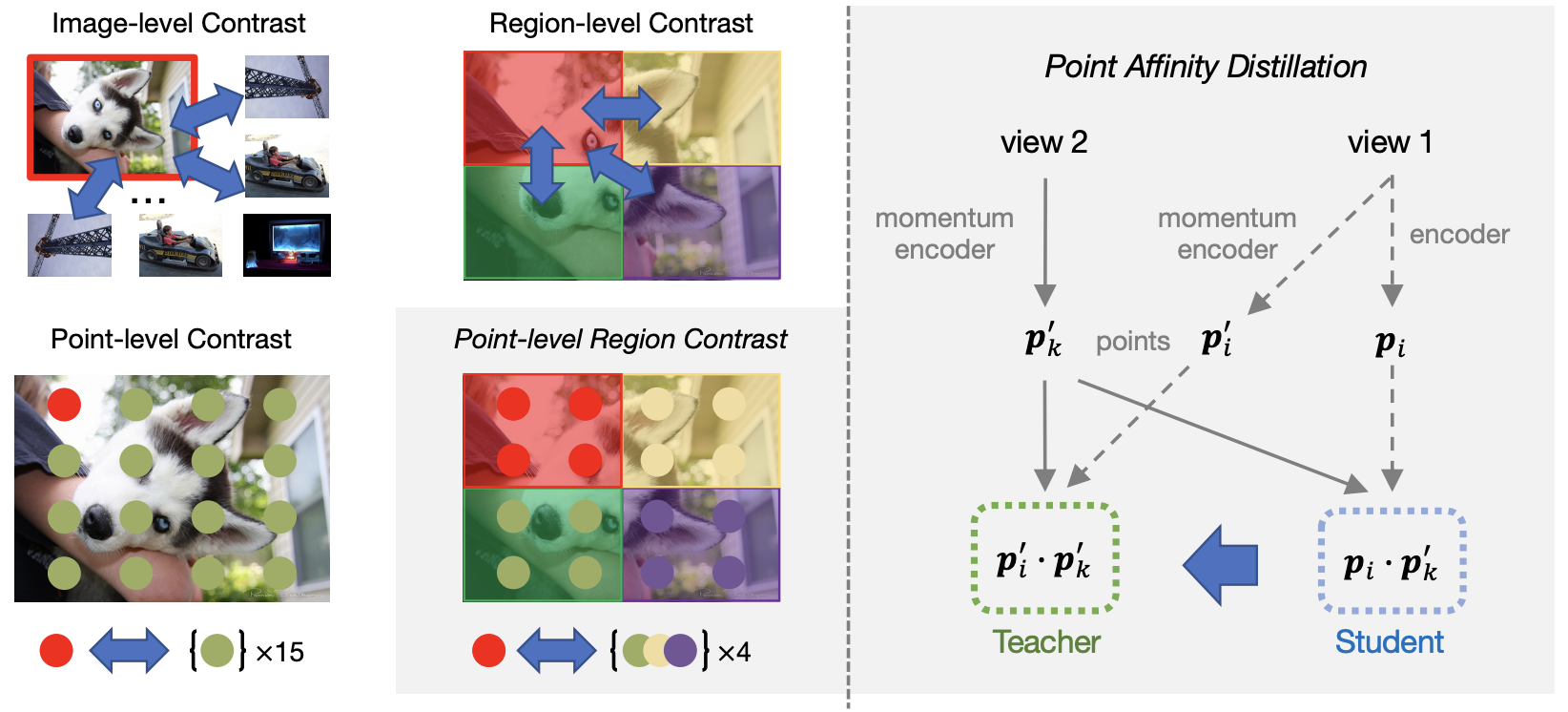
Point-Level Region Contrast for Object Detection Pre-Training
Yutong Bai , Xinlei Chen Alexander Kirillov Alan Yuille Alexander C. Berg (Nominated for CVPR Best Paper - Top 0.4%)
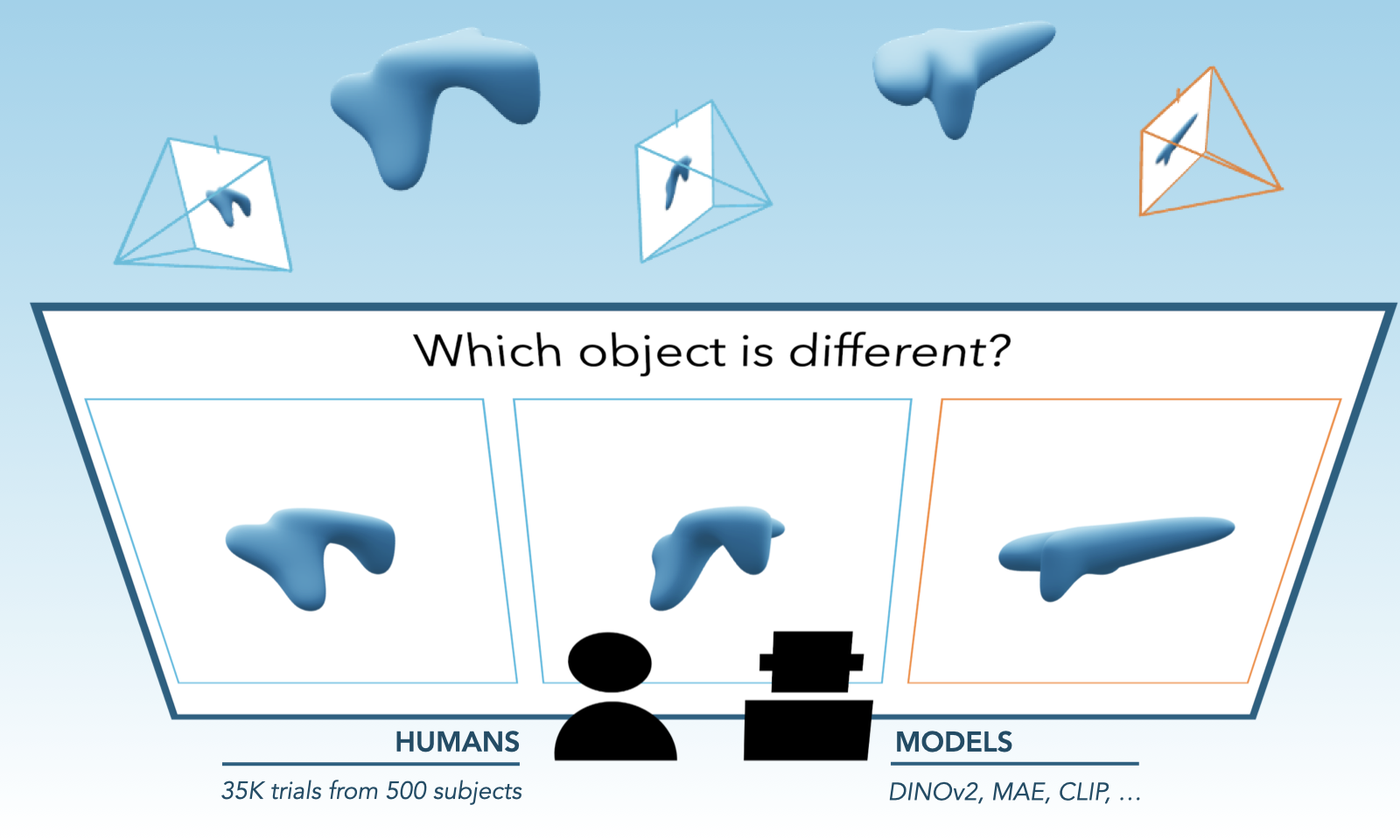
Evaluating Multiview Object Consistency in Humans and Image Models
Tyler Bonnen , Stephanie Fu , Yutong Bai , Thomas O'Connell , Yoni Friedman , Nancy Kanwisher , Josh Tenenbaum , Alexei Efros
Intriguing Properties of Text-guided Diffusion Models
Qihao Liu , Adam Kortylewski , Yutong Bai , Song Bai , Alan Yuille
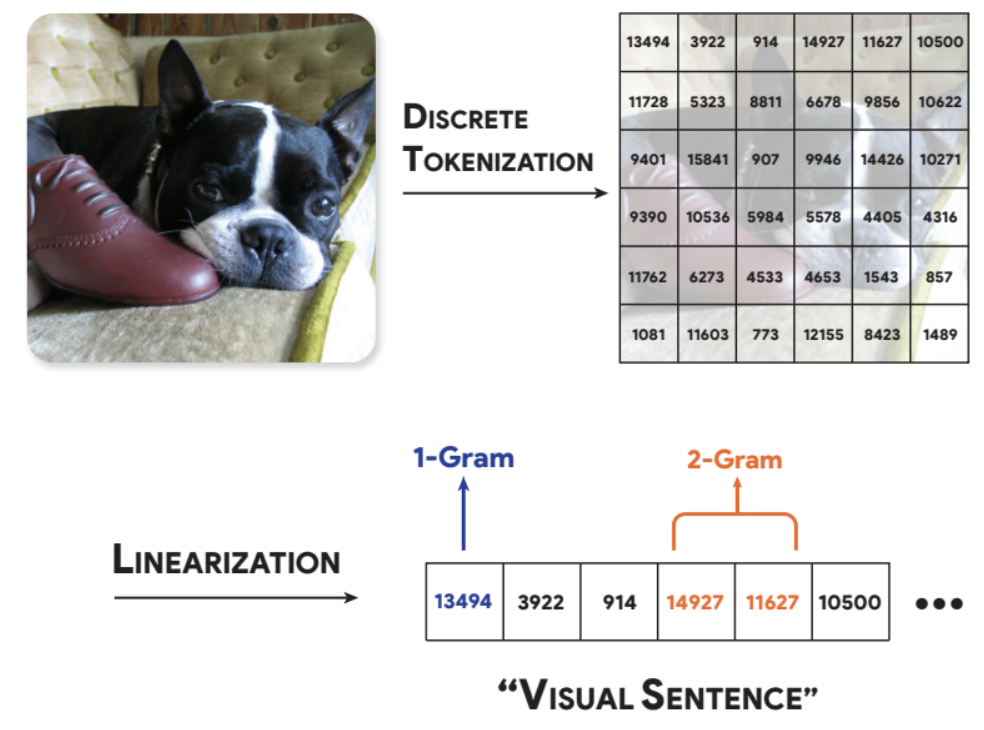
Analyzing The Language of Visual Tokens
David M Chan , Rodolfo Corona , Joonyong Park , Cheol Jun Cho , Yutong Bai , Trevor Darrell
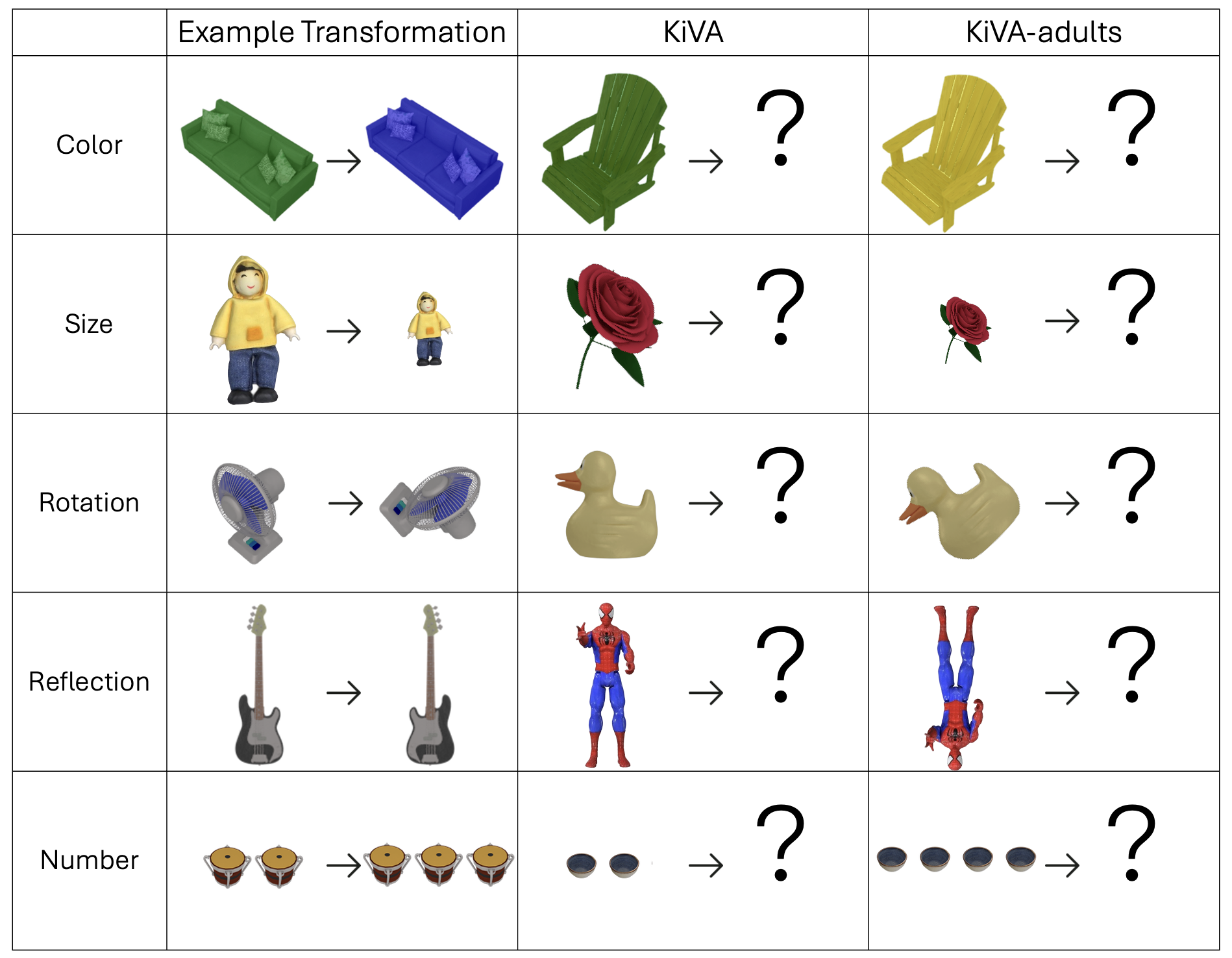
KiVA: Kid-inspired Visual Analogies for Testing Large Multimodal Models
Eunice Yiu , Maan Qraitem , Anisa Noor Majhi , Charlie Wong , Yutong Bai , Shiry Ginosar , Alison Gopnik , Kate Saenko
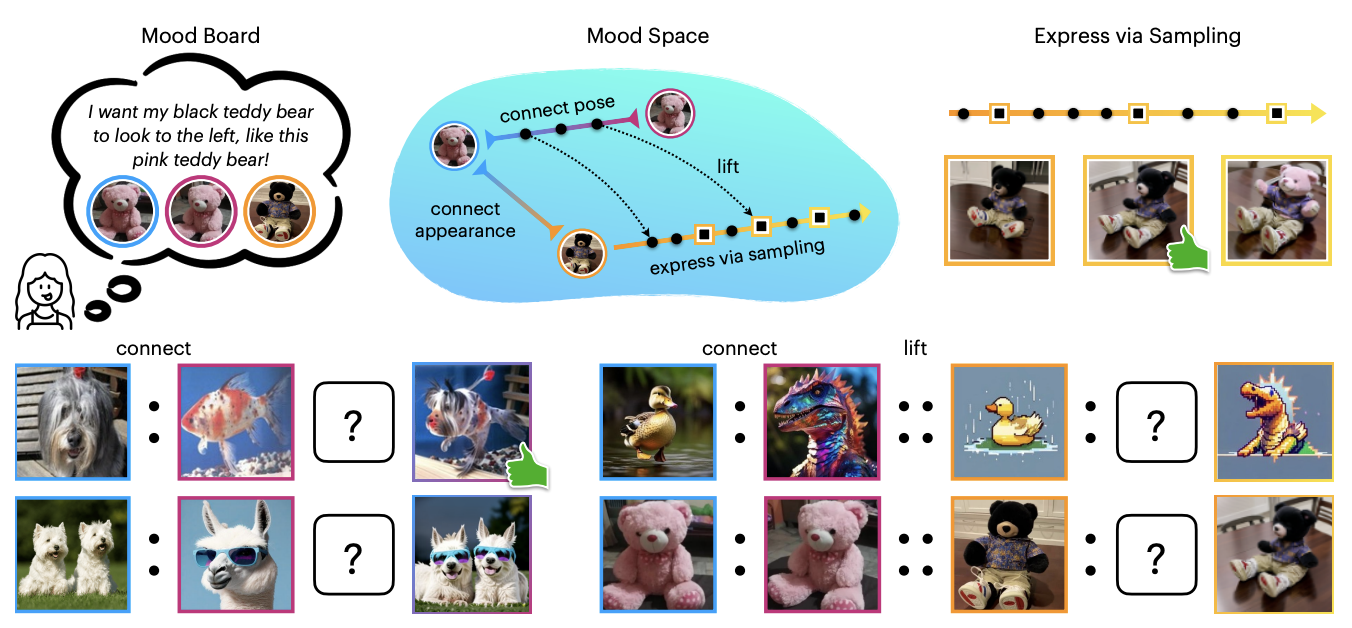
Vibe Spaces for Creatively Connecting and Expressing Visual Concepts
Huzheng Yang , Katherine Xu , Andrew Lu , Michael D. Grossberg , Yutong Bai , Jianbo Shi
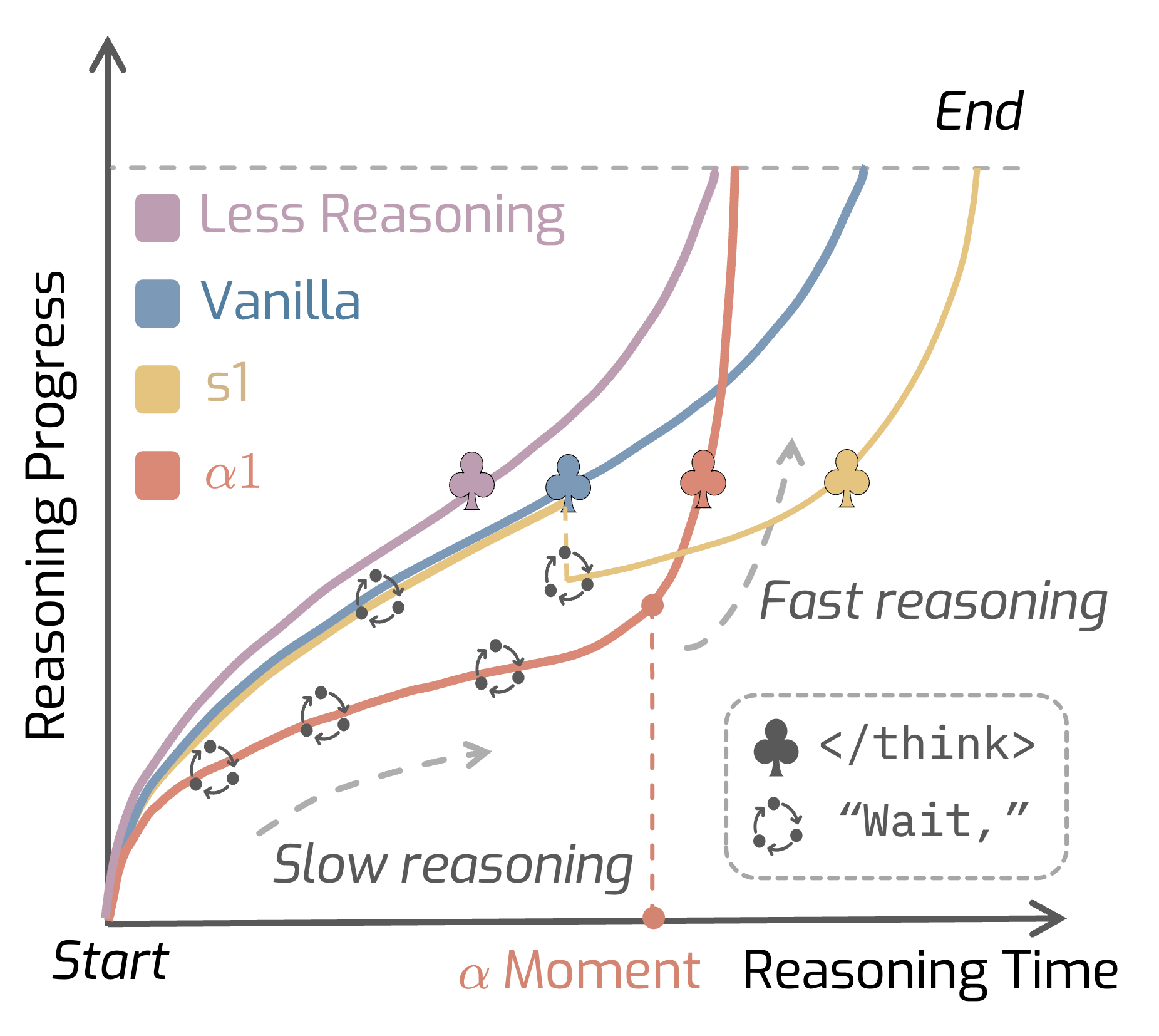
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
Junyu Zhang , Runpei Dong , Han Wang , Xuying Ning , Haoran Geng , Peihao Li , Xialin He , Yutong Bai , Jitendra Malik , Saurabh Gupta , Huan Zhang
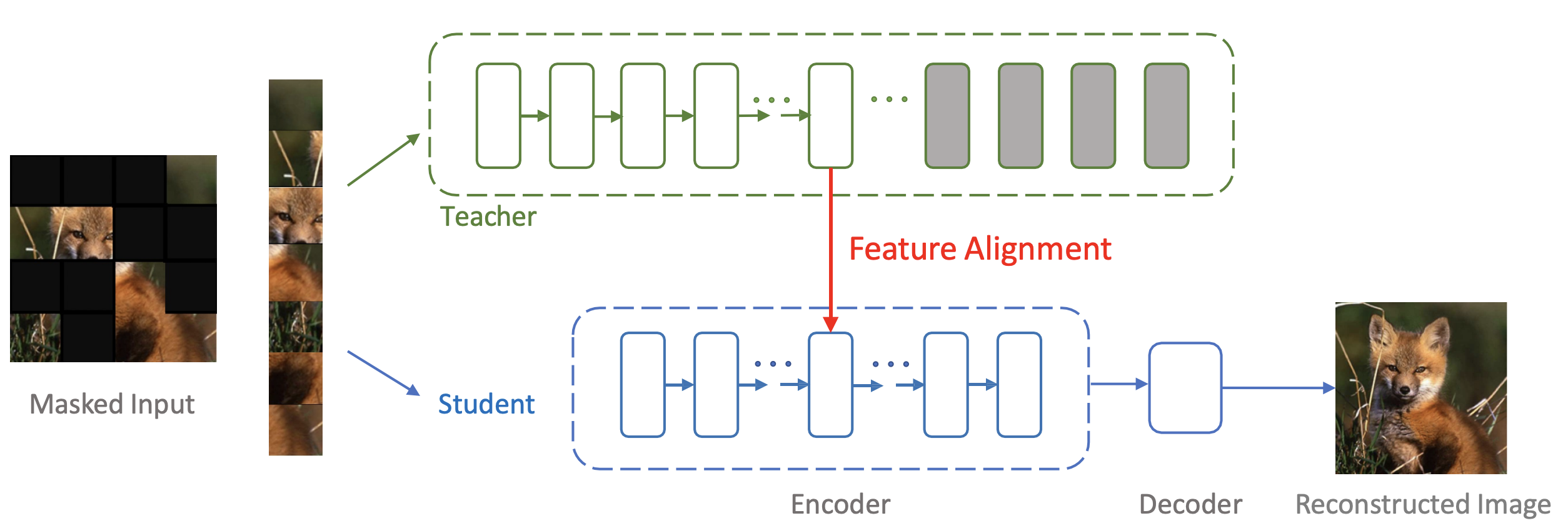
Masked Autoencoders Enable Efficient Knowledge Distillers
Yutong Bai , Zeyu Wang , Junfei Xiao , Chen Wei , Huiyu Wang , Alan L Yuille Yuyin Zhou , Cihang Xie
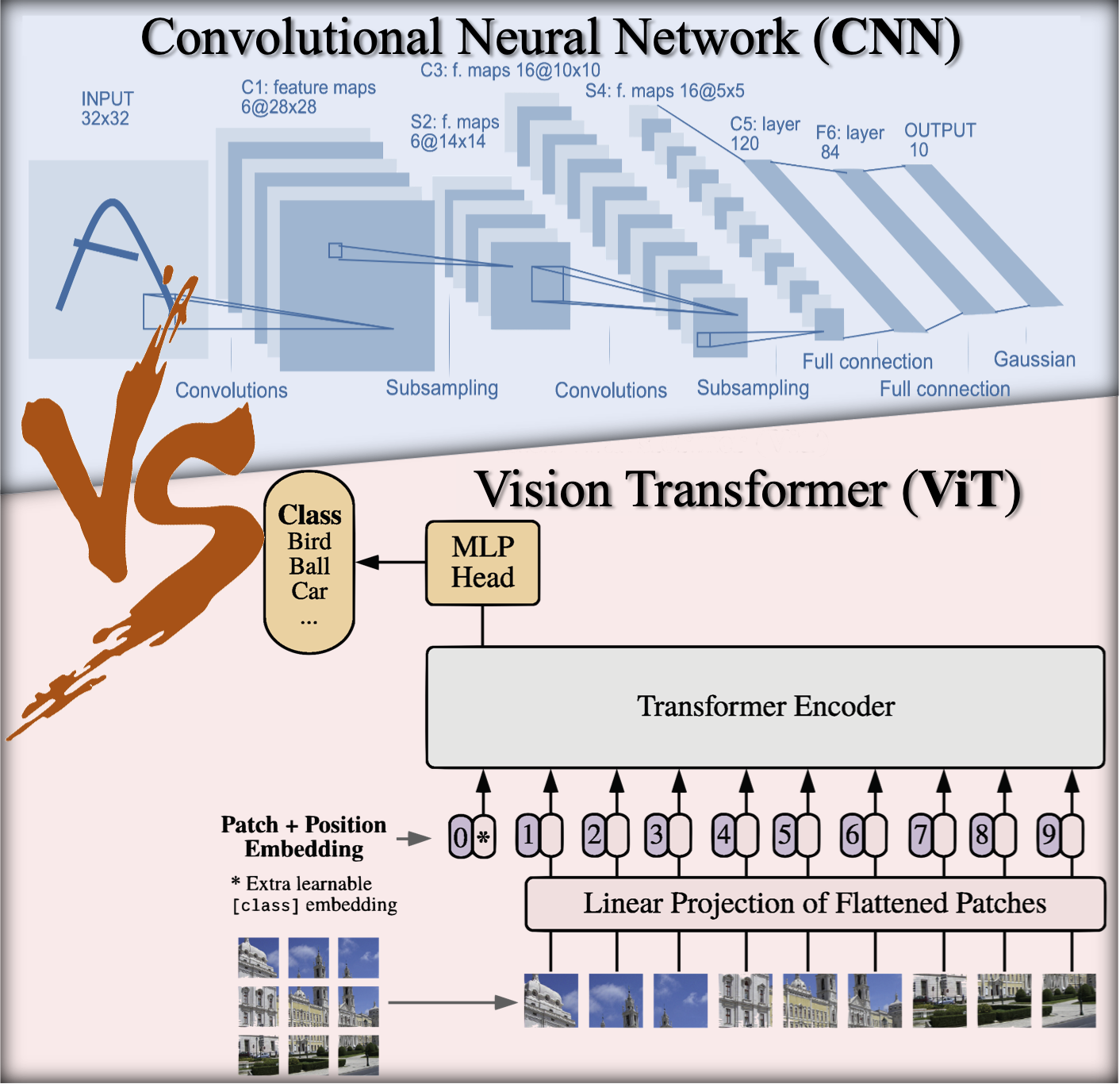
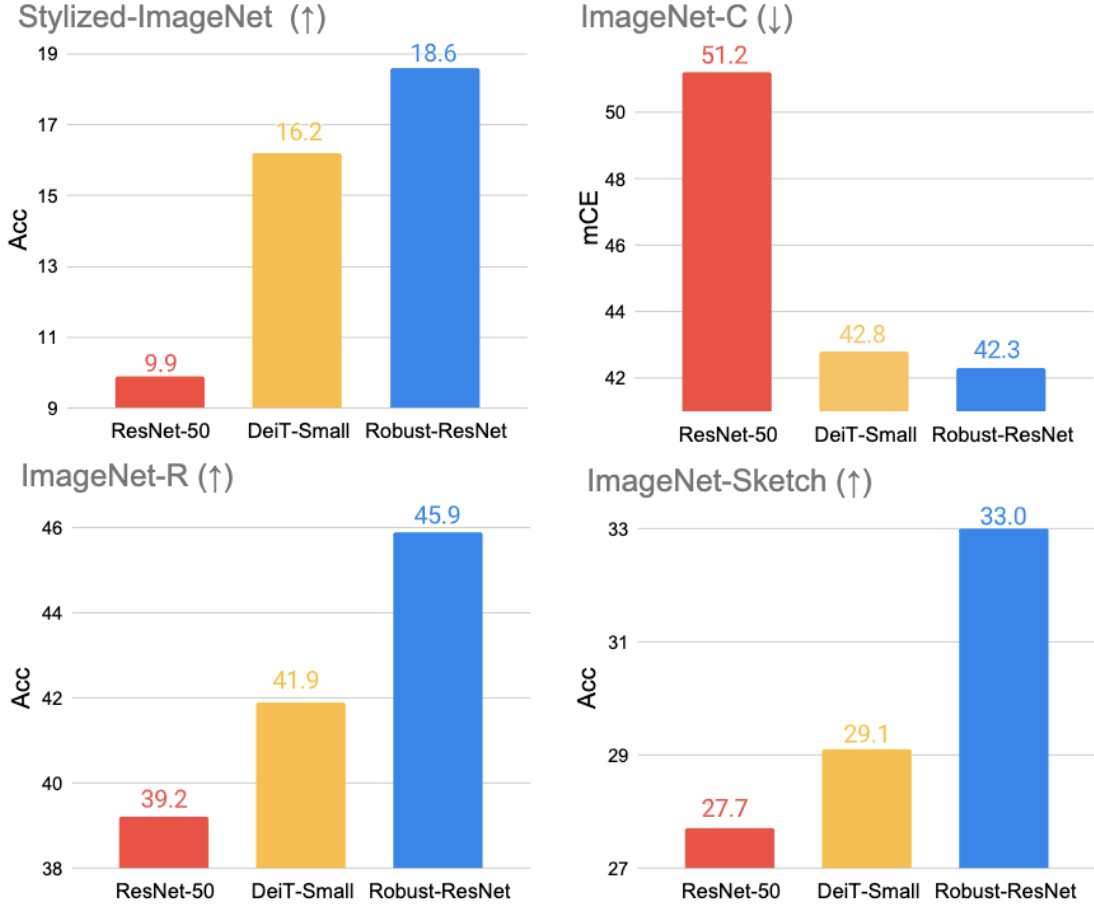
Are Transformers More Robust than CNNs?
Yutong Bai , Jieru Mei , Alan Yuille Cihang Xie
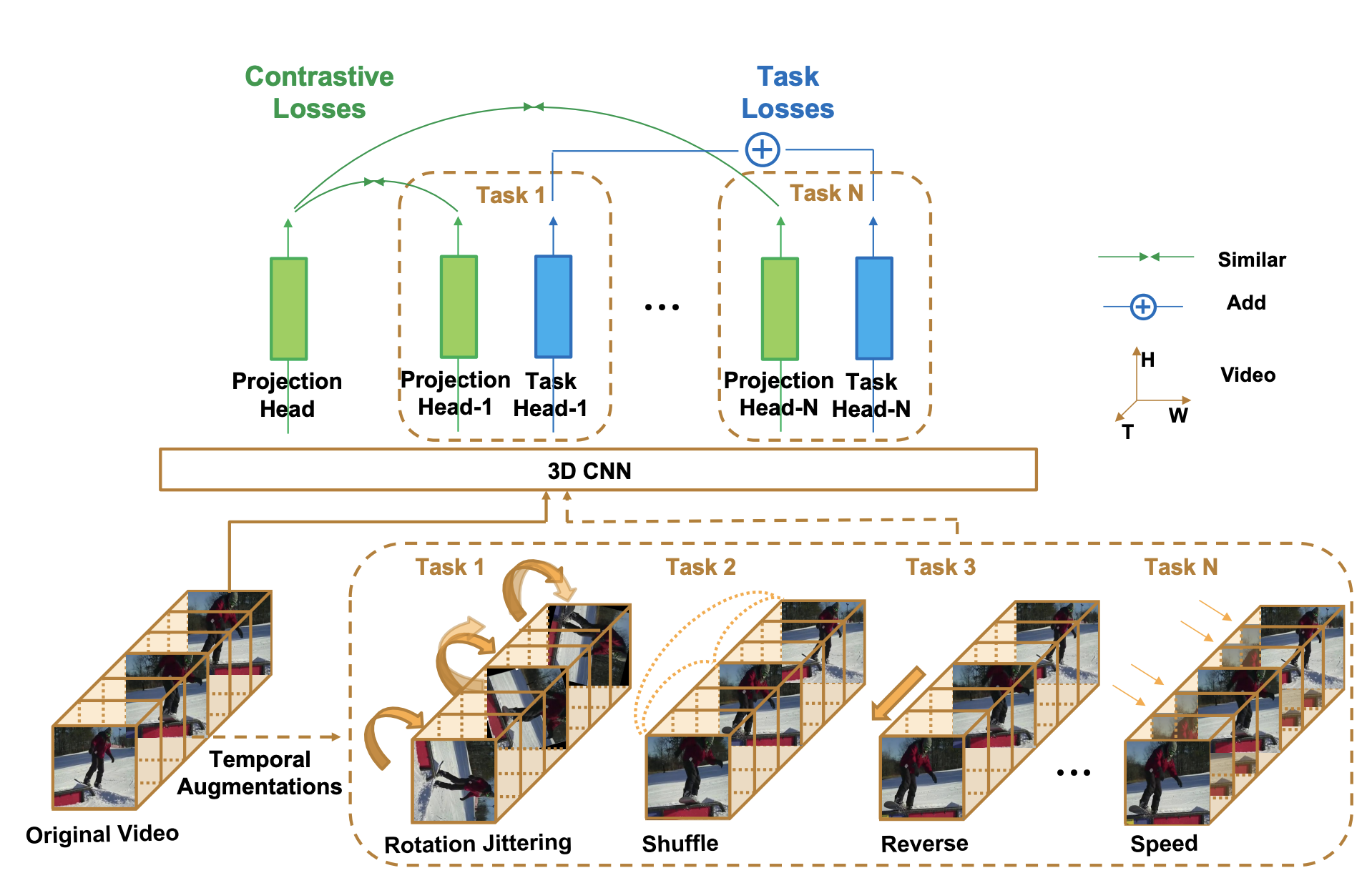
Can Temporal Information Help with Contrastive Self-Supervised Learning?
Yutong Bai ,
Haoqi Fan ,
Ishan Misra ,
Ganesh Venkatesh ,
Yongyi Lu ,
Yuyin Zhou ,
Qihang Yu ,
Vikas Chandra ,
Alan Yuille
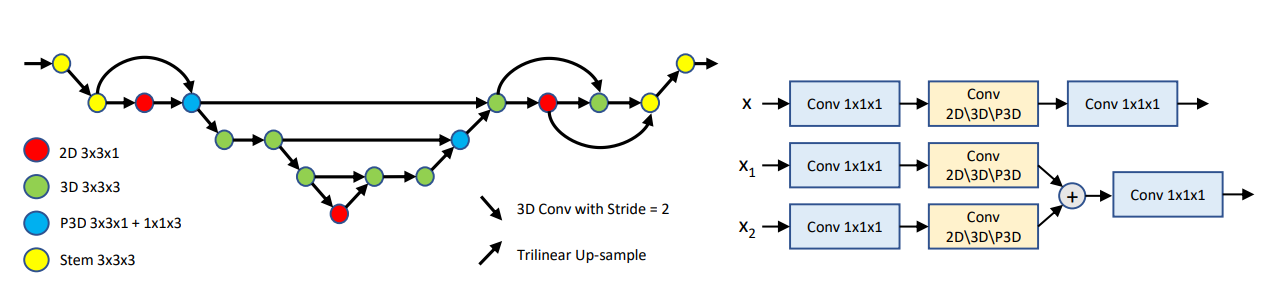
C2FNAS: Coarse-to-Fine Neural Architecture Search for 3D Medical Image Segmentation
Qihang Yu ,
Dong Yang ,
Holger Roth ,
Yutong Bai ,
Yixiao Zhang ,
Alan Yuille Daguang Xu
Semantic Part Detection via Matching: Learning to Generalize to Novel Viewpoints from Limited Training Data
Yutong Bai , Qing Liu , Lingxi Xie , Weichao Qiu , Yan Zheng , Alan Yuille
Clevr-ref+: Diagnosing Visual Reasoning with Referring Expressions
Runtao Liu , Chenxi Liu , Yutong Bai , Alan L Yuille
CoKe: Contrastive Learning for Robust Keypoint Detection
Yutong Bai , Angtian Wang , Adam Kortylewski , Alan Yuille
Delving Into Masked Autoencoders for Multi-Label Thorax Disease Classification
Junfei Xiao , Yutong Bai , Alan Yuille Zongwei Zhou
REOrdering Patches Improves Vision Models
Declan Kutscher , David M Chan , Yutong Bai , Trevor Darrell , Ritwik Gupta
AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information?
Kaixiong Gong , Kaituo Feng , Bohao Li , Yibing Wang , Mofan Cheng , Shijia Yang , Jiaming Han , Benyou Wang , Yutong Bai , Zhuoran Yang , Xiangyu Yue
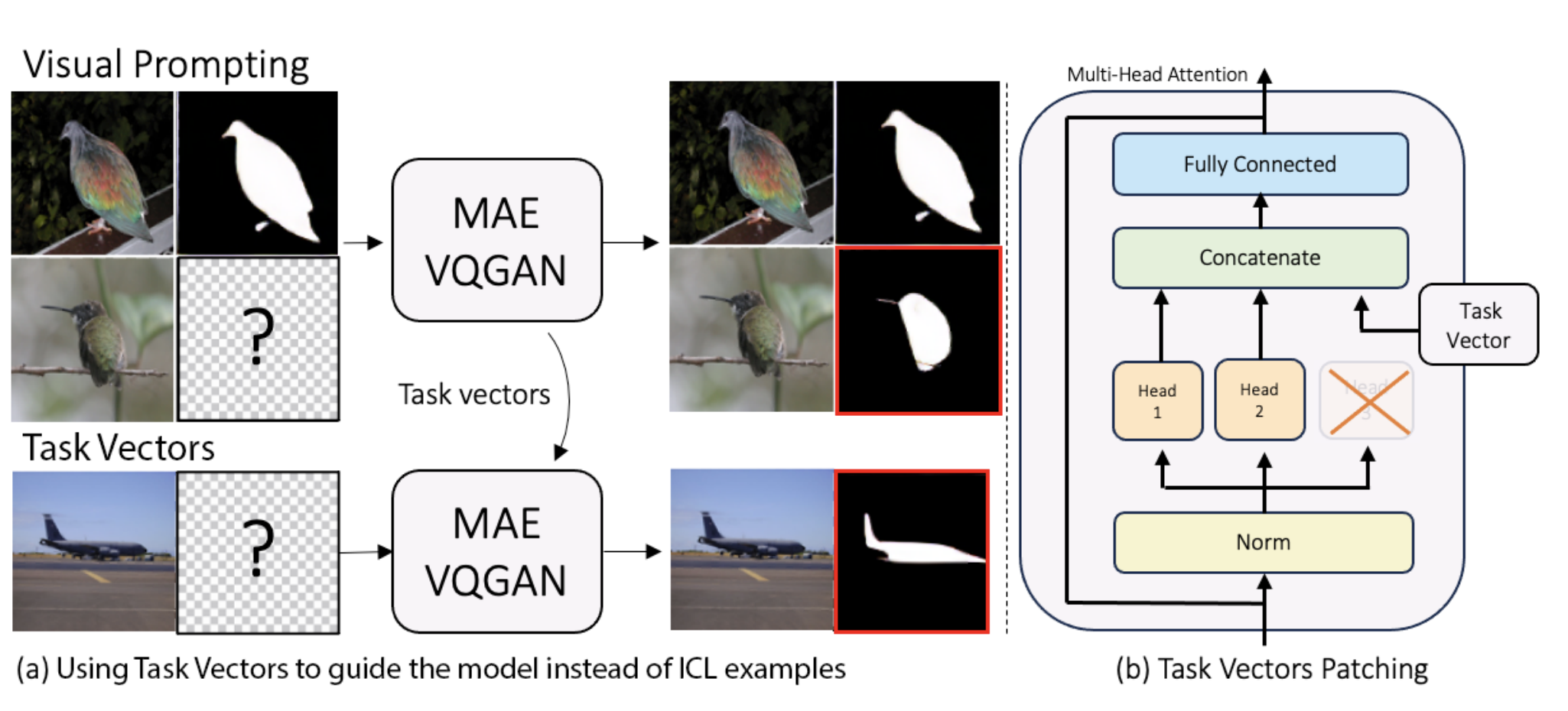
Finding Visual Task Vectors
Alberto Hojel , Yutong Bai , Trevor Darrell , Amir Globerson , Amir Bar
Mask Guided Matting via Progressive Refinement Network
Qihang Yu , Jianming Zhang , He Zhang , Yilin Wang , Zhe Lin , Ning Xu , Yutong Bai , Alan Yuille
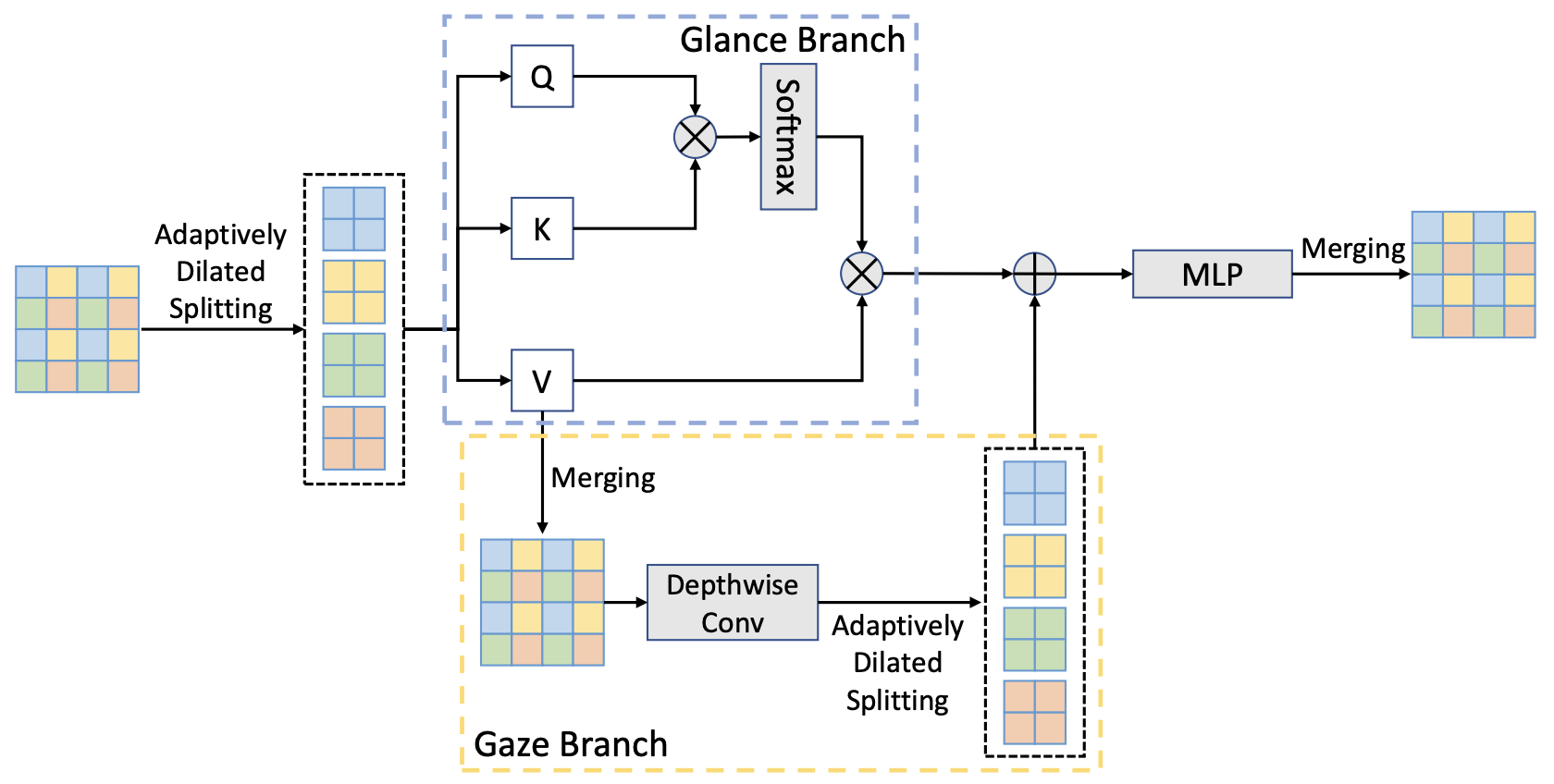
Glance-and-Gaze Vision Transformer
Qihang Yu , Yingda Xia , Yutong Bai , Yongyi Lu , Alan L. Yuille , Wei Shen
Can CNNs Be More Robust Than Transformers?
Zeyu Wang , Yutong Bai , Yuyin Zhou , Cihang Xie
LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning
Dantong Niu , Yuvan Sharma , Giscard Biamby , Jerome Quenum , Yutong Bai , Baifeng Shi , Trevor Darrell , Roei Herzig
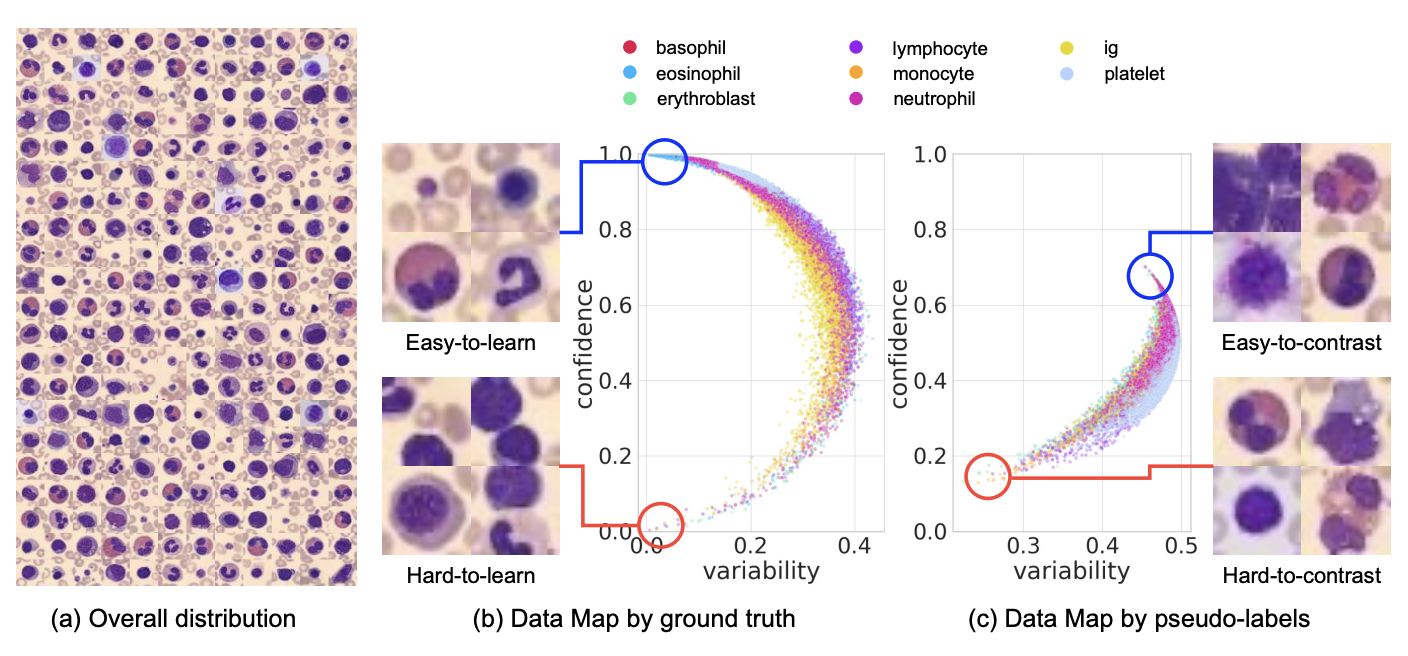
Making Your First Choice: To Address Cold Start Problem in Medical Active Learning
Liangyu Chen , Yutong Bai , Siyu Huang , Yongyi Lu , Bihan Wen , Alan Yuille , Zongwei Zhou
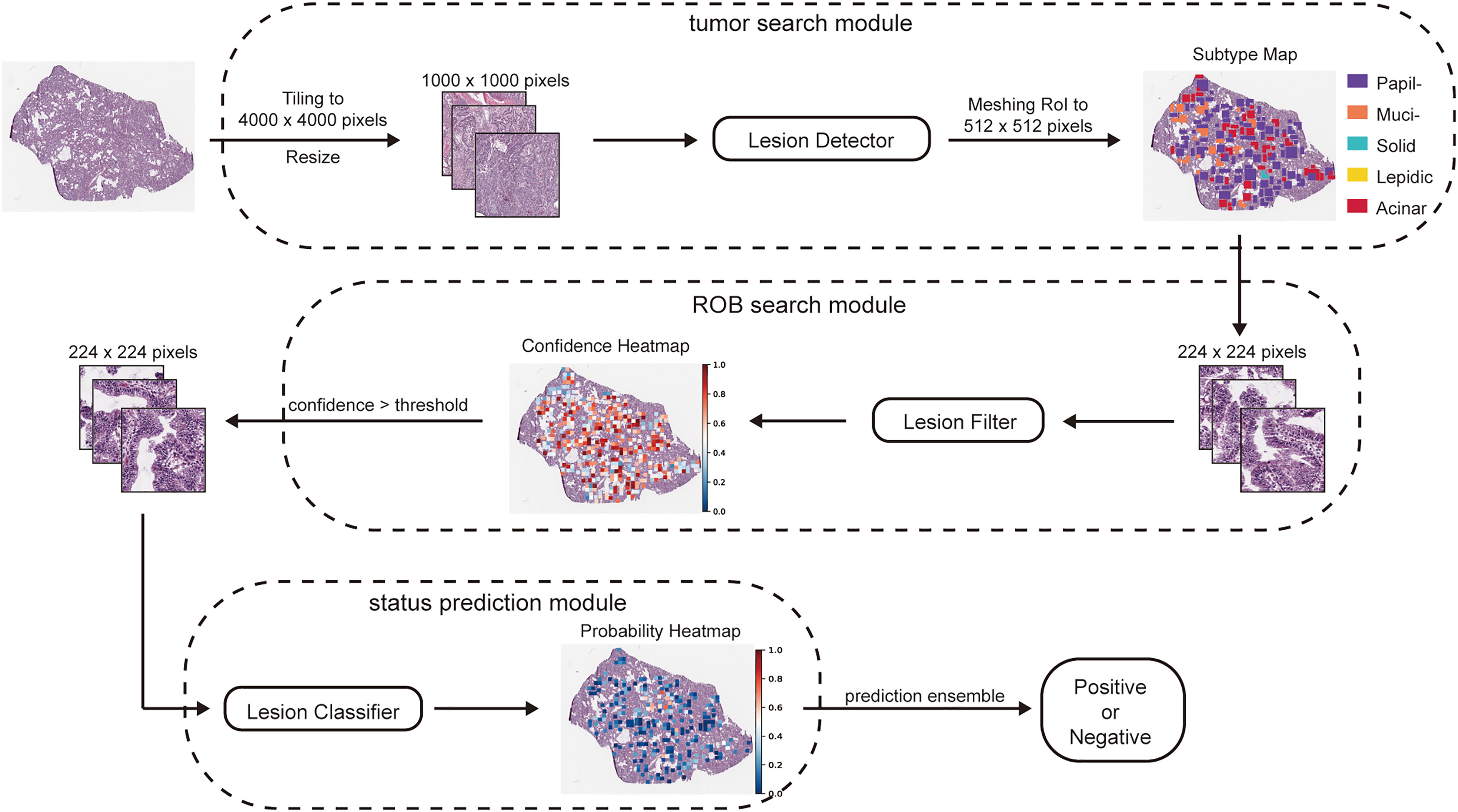
Focalizing regions of biomarker relevance facilitates biomarker prediction on histopathological images
Jiefeng Gan , Hanchen Wang , Hui Yu , Zitong He , Wenjuan Zhang , Ke Ma , Lianghui Zhu , Yutong Bai , Zongwei Zhou , Alan Yullie , Xiang Bai , Mingwei Wang , Dehua Yang , Yanyan Chen , Guoan Chen , Joan Lasenby , Chao Cheng , Jia Wu , Jianjun Zhang , Xinggang Wang , Yaobing Chen , Guoping Wang , Tian Xia
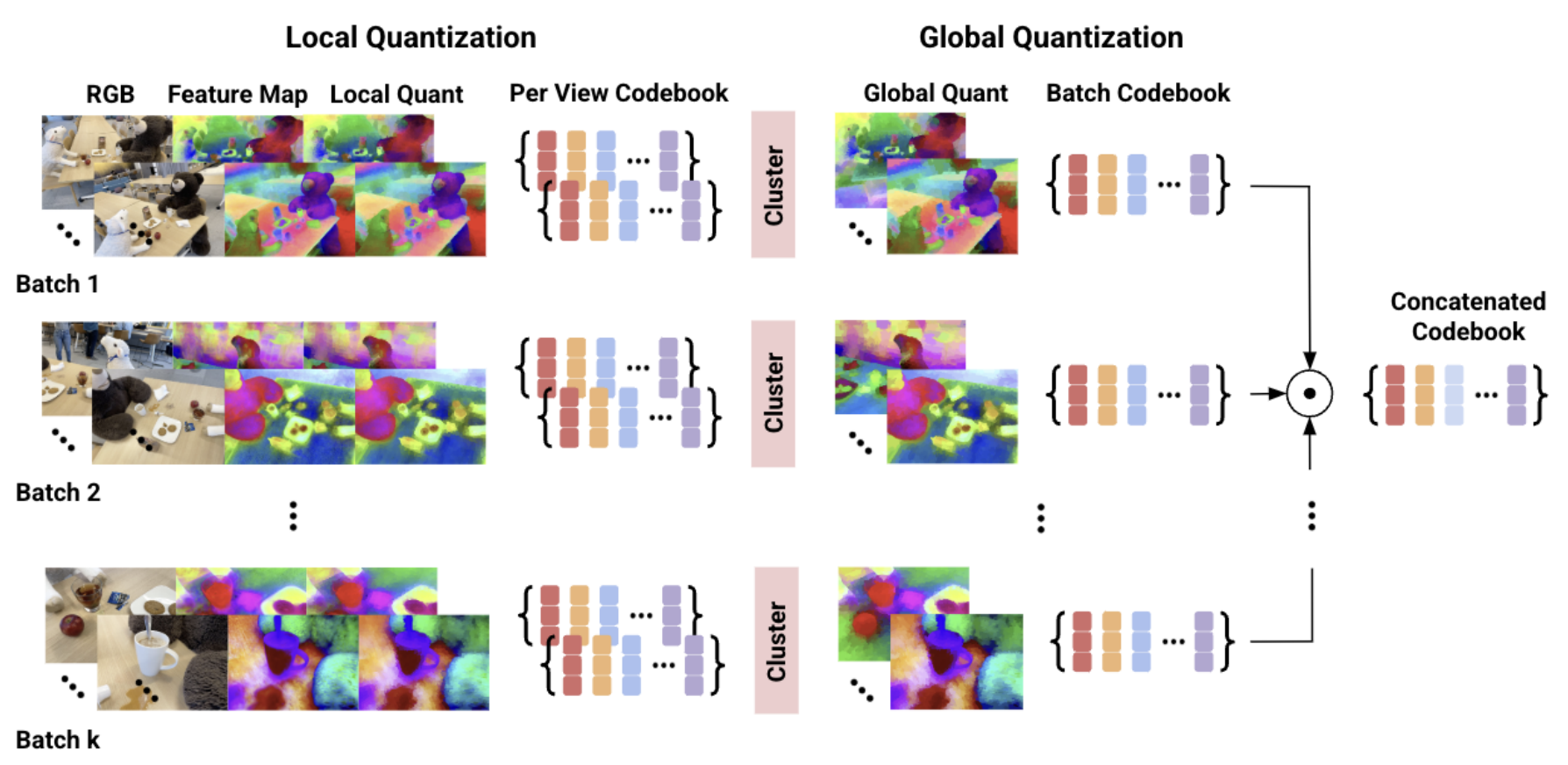
Vector Quantized Feature Fields for Fast 3D Semantic Lifting
George Tang , Aditya Agarwal , Weiqiao Han , Trevor Darrell , Yutong Bai
Fast AdvProp
Jieru Mei , Yucheng Han , Yutong Bai , Yixiao Zhang , Yingwei Li , Xianhang Li , Alan Yuille , Cihang Xie